


말하는 AI? 노래하는 AI?
VMONSTER TEAM
May 27, 2025
1. AI 아바타의 핵심 기술 토킹 포토 (Talking Photo)
안녕하세요. 오늘은 AI 아바타의 핵심 기술인 토킹 포토 생성에 대해서 얘기해보려고 합니다. 토킹 포토 생성 (Talking Photo Generation) 혹은 토킹 헤드 제너레이션 (Talking Head Generation)은 주어진 인물의 얼굴 사진과 음성을 이용해서 그 인물이 말하는 영상을 생성하는 AI 기술의 한 분야입니다. 이때, 사용하는 음성은 반드시 그 해당 인물의 음성일 필요는 없고, 사용자가 임의로 선택할 수 있습니다. 예를 들면, 제가 만든 아바타의 얼굴에 제 목소리를 입혀 저만의 AI 아바타를 만들 수 있는 거죠. 어때요 정말 멋진 기술 아닌가요?
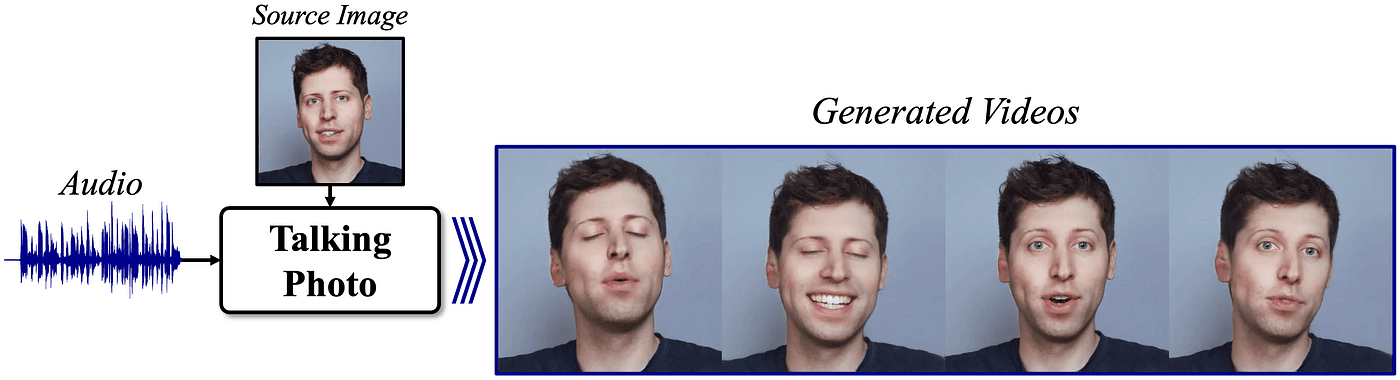
<토킹포토 (Talking Photo) 기술 개요도. 얼굴 사진 (Source Image)과 음성 (Audio)로 말하는 영상 생성>
2. 토킹 포토의 맹점과 그 역사
멋진 기술인 만큼, 토킹 포토 기술은 AI 분야에서도 상당히 복잡하고, 복합적인 기술 분야 속하는 편입니다. 그렇다보니 학계에서도 본격적인 연구가 시작된게 약 6년 전으로 다른 주류 AI 기술들에 비해 그리 오래 되지 않았습니다.

<토킹 포토 예시. Wav2Lip (Prajwal, K. R., et al.) >
2020년, Wav2Lip (Prajwal, K. R., et al.) 이라는 토킹포토 기술이 등장하였습니다. Wav2Lip 기술의 핵심은 주어진 사진 혹은 영상의 입 (mouth or lip)을 까맣게 가린 뒤 (masking) 그 가려진 입모양을 오디오에서부터 예측하는 것이었습니다. 처음 설명드린 것과 마찬가지로, 이때 사용되는 오디오는 그 인물의 실제 목소리와 상관 없는 오디오도 가능했었고, 이것을 처음 본 사람들은 본인과 직접 대화하는 AI 아바타에 대한 가능성을 처음으로 떠올리게 되었죠.

<토킹 포토 예시. Wav2Lip (Prajwal, K. R., et al.) >
Wav2Lip은 AI 연구자들에게 새로운 연구분야를 제시해 줌과 동시에 해결해야할 질문을 남겨주었습니다. 바로
“어떻게 하면 실제 사람과 구분하기 어려울 수준의, 실제 사람과 극도로 닮은 영상을 만들 수 있을까?
에 대한 것이었죠. 최근까지의 연구된 모든 토킹 포토 연구 논문 결과들은 그 형태는 달라도 모두 이 맹점 하나를 가지고 발전되어 왔습니다. 그렇다면 어떤 요소들이 “실제와 구분하기 어려울 정도의 사실성”을 결정 짓는 걸까요?
첫번째는 오디오에 맞는 정확한 입모양 (Lip Syncing)입니다.
흔히 립싱킹 (lip syncing)이라고 불리우는 이 요소는 Wav2Lip이 공개된 시점부터 토킹포토 기술의 퀄리티를 결정하는 핵심 요소였습니다. 쉽게 말하자면, 영상이 말을 할 때, 현재 음성과 어긋난 입모양을 하고 있으면 영상을 보는 사람이 이 영상이 실제같지 않다고 생각하겠죠? 이것을 결정하는 요소가 립싱킹입니다.
최근에는 관련 연구분야에서 널리 쓰이는 LSE-D, LSE-C 와 같은 수치적/정량적 지표 (quantitative metric)로 잘 드러나지 않는 립싱킹 정확도를 판단하기 위해, “노래”와 같은 입력 오디오를 사용해 생성한 영상을 정성적 지표 (qualitative results)를 많이 활용하고 있습니다. 아무래도 노래는 일반 발화 음성과 다르게 음율, 배경음 등이 포함되어 있으니 더 challenging하니까요. 이 덕분에 노래 부르는 AI 라는 이름으로 사람들의 주목을 받기도 했었죠.
두번째는 자연스러운 머리의 움직임 (natural head motion) 입니다.
Wav2Lip의 가장 핵심적인 문제점은 입을 제외한 영역은 생성하지 못한다는 점입니다. 그 이유는 Wav2Lip이라는 모델 자체가 애초에 입을 까맣게 가리고 그 빈 영역을 예측하는 방식으로 학습되기 때문입니다. 그렇기 때문에 Wav2Lip에서는 입력이 사진 한 장일 경우 입을 제외한 다른 얼굴 영역과 머리 움직임은 고정된 상태로 입만 뻐끔뻐끔거리는, 다소 어색한 토킹 포토를 생성하게 되는거죠. 입력으로 사진 ‘한 장’이 아닌 ‘영상’을 줄 수도 있지만, 이 경우 입을 제외한 영역을 원본 영상을 따라가면서 말하게 되다보니, 실제 음성과 맞지 않는 머리 움직임으로 말을 하게 될 수 있는 거죠.
그런데 사실, 잘 생각해보면 음성에 맞는 머리 움직임을 생성한다는 건 생각보다 쉽지 않은 문제입니다. 입 움직임과는 다르게, 머리의 움직임은 주어진 오디오와의 대응관계가 상대적으로 약하기 때문이죠. 예를 들어, “오늘 하루도 고생하셨습니다.” 라는 음성의 입 움직임은 사람마다 크게 차이가 없겠지만, 그에 따른 머리 움직임은 사람마다 크게 다를 수 있잖아요? 어떤 사람은 고개를 살짝 끄덕이면서 말할 수도 있고, 어떤 사람은 무덤덤히 거의 움직이지 않을 수도 있고요. 두 움직임 모두 음성에 크게 이질적이게 느껴지지 않을 수 있는 거죠.
이러한 문제를 해결하기 위해, AI 연구자들은 음성에 맞는 정확한 하나의 머리 움직임 예측하는 것이 아닌, 확률적 모델링 (probabilistic modeling)을 통해 그럴듯한 (plausible) 머리 움직임으로 확률적으로 매칭하는 방식으로 문제를 바꿔서 접근했습니다. 확률적 모델링에 대해서는 기회가 되면 추후에 좀 더 자세히 다루도록 하겠습니다. 어찌되든, 이 접근 방식의 핵심은 확률형 생성 모델 (probabilistic generative model)을 이용해서 현재 주어진 오디오에 맞는 “그럴듯한” 머리 움직임을 생성할 뿐, 정해진 하나의 머리 움직임 생성을 강요하지 않는 방식이라는 겁니다. 이러한 접근 방식은 토킹 포토 모델이 더 자유롭게 머리 움직임을 생성하도록 만드는 셈인거죠.

이러한 접근의 초기 연구들은 대표적인 생성 모델인 Variational inference (Kingma, D. P. et. al., Auto-encoding variational bayes.) 나 Normalizing flow (Rezende, D., et. al., Variational inference with normalizing flows.)를 통해서 머리 움직임을 생성하도록 시도하였습니다만, 그렇게까지 자연스러운 머리 움직임을 생성하지는 못했습니다. 이 생성 모델들 자체의 생성 능력 (capacity)이 강력하지 못했거든요.
그러나 최근에는 diffusion model이나 flow matching과 같은 기존 대비 생성 능력이 더 뛰어난 확률 모델링이 등장함에 따라 이들을 이용한 더 자연스러운 머리 움직임을 생성할 수 있는 경지에 이르렀습니다.

<Diffusion model을 이용한 머리 움직임 생성. VASA-1>

<Flow matching을 이용한 머리 움직임 생성. FLOAT>
세번째는 자연스러운 감정 표현입니다.
사람은 말을 할 때 자연스럽게 그 감정을 표현합니다. 음성에는 듣기만 해도 행복한 기분이 담겨 있지만, 토킹 포토는 무표정하게 말을 한다면 어떨까요? 아마 말과 표정이 일치 하지 않는 어색함 때문에, 실제보단 만들어진 영상이라고 생각하지 않을까요? 감정을 표현하고, 그 감정의 단계까지 조절 가능한 토킹 포토는 어쩌면 실제 사람 영상과의 구분을 어렵게 만드는, 미묘하면서도 가장 중요한 요소가 아닐까 싶습니다. 하지만 앞선 두 문제를 풀어내는데에도 꽤 오랜 시간이 걸렸기에, 자연스러운 감정까지 표현하는 토킹 포토는 본격적인 연구가 시작된지 불과 2년 정도밖에 되지 않았습니다.
연구자들은 자연스러운 감정을 담은 토킹 포토를 해결하기 위해, 다양한 감정을 담은 사람 발화 영상 데이터를 고안하는 단계부터 시작하였습니다. 최근에는 이러한 데이터들을 기반으로 diffusion model과 flow matching에 input으로 사용할 음성과 함께 일곱가지 기본 감정 (Happy, Sad, Disgust, Angry, Neutral, Surprised, Fear) 의 확률 값을 주입하는 방식으로 어느정도 감정 조절이 가능한 토킹포토를 개발하는 것에 성공했습니다.

<Diffusion model을 이용한 감정 조절. VASA-1>
하지만, 더 다양한 감정 조절을 하는 것은 여전히 어려운 문제로 남아있습니다. 예를 들어, “부끄러움”이나 “당혹감” 같은 복합적인 감정들은 앞서 언급한 일곱가지 감정의 조합만으로 표현하기에 어려우니까요.
3. 그렇다면 현재 학계에서는 어떤 것을 더 연구하고 있을까
위의 세 가지 요소 모두 AI 기술이 발전과 함께, 현재 높은 수준까지 도달했습니다. 그렇다면 이 세가지 요소만 더 극대화하면 완벽한 토킹포토 기술이라고 할 수 있을까요? 혹시 다른 요소가 더 있지는 않을까요?
토킹 포토 기술의 맹점은 “실제 사람과 구분되지 않은 정도의 자연스러움”이었습니다. 그러한 맹점과 관련된 것이라면 어떠한 것이든 새로운 연구주제가 될 수 있습니다.
얼굴을 넘어선 상반신 또는 전신의 움직임
최근 학계의 가장 큰 흐름 중 하나는 얼굴 영역을 넘어 상반신과 전신으로 생성하는 움직임의 범위를 확장하는 것입니다. 생각해보면 얼굴 뿐 아니라 손 동작이나 몸 동작까지 자유롭게 생성할 수 있다면, 보다 더 실감나는 AI 아바타를 만나볼 수 있겠죠.
Press enter or click to view image in full size
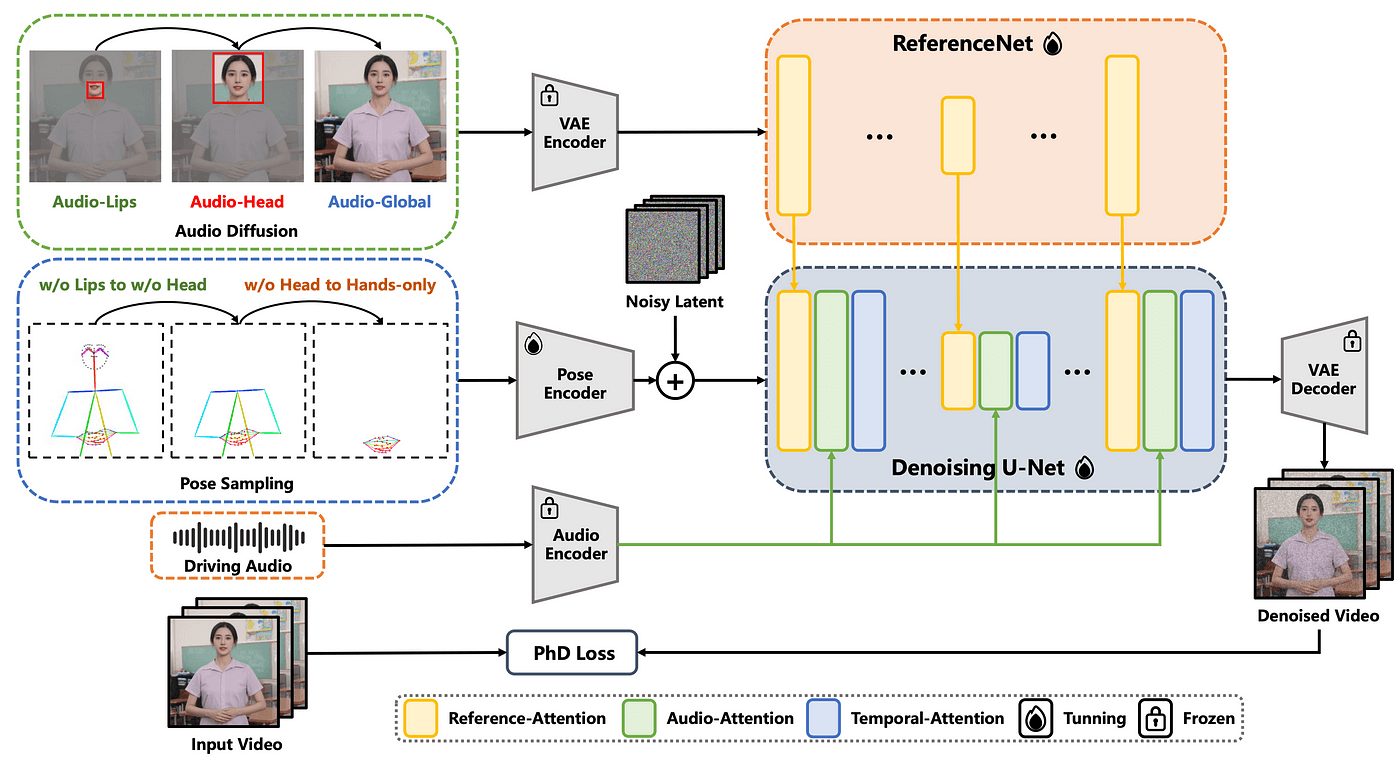
<오디오에서 손동작을 생성하는 토킹 포토. EchoMimicV2>
<오디오에서 손동작을 생성하는 토킹 포토. EchoMimicV2>
가장 대표적 최신 연구인 EchoMimicV2 (CVPR 2025)는 실제 사람의 손짓을 생성하기 위해 diffusion model을 이용해, 인물 사진 한 장, 오디오, 그리고 손 이미지들로부터 상반신이 움직이는 비디오를 생성합니다. 하지만, 이 연구 방향은 학습용으로 공개된 좋은 데이터도 부족하고, 방법론이 실험적 단계에 머물러 있기 때문에 여전히 부족한 점이 많이 있습니다. 마치 초기 토킹 헤드 연구에서 정확한 입 움직임을 만드는데 집중한 것 처럼, 지금 이 분야에서는 정확한 움직임을 만드는 것에 어려움을 겪고 있습니다. 그렇다 보니 이러한 데이터를 자체적으로 수급할 수 있는 Tiktok 같은 영상 컨텐츠를 다루는 대기업들이 주로 연구를 주도하고 있는 상황입니다. 몇 초짜리 영상을 생성하는데에 수십분의 시간이 필요하기도 하고요.
4. 반응형 (responsive) 토킹 포토
기존 토킹 포토는 AI가 말하게 하는 것, 즉 정보를 전달 (deliver) 하는 데에 크게 초점이 맞춰져 있었습니다. 하지만 실제로 사용자가 AI 아바타와 대화하는 시나리오를 생각해보면, 사용자의 말을 인식하고, 적절한 반응 (respond)을 할 수 있을 때, 비로소 소통한다는 느낌이 들지 않을까요?
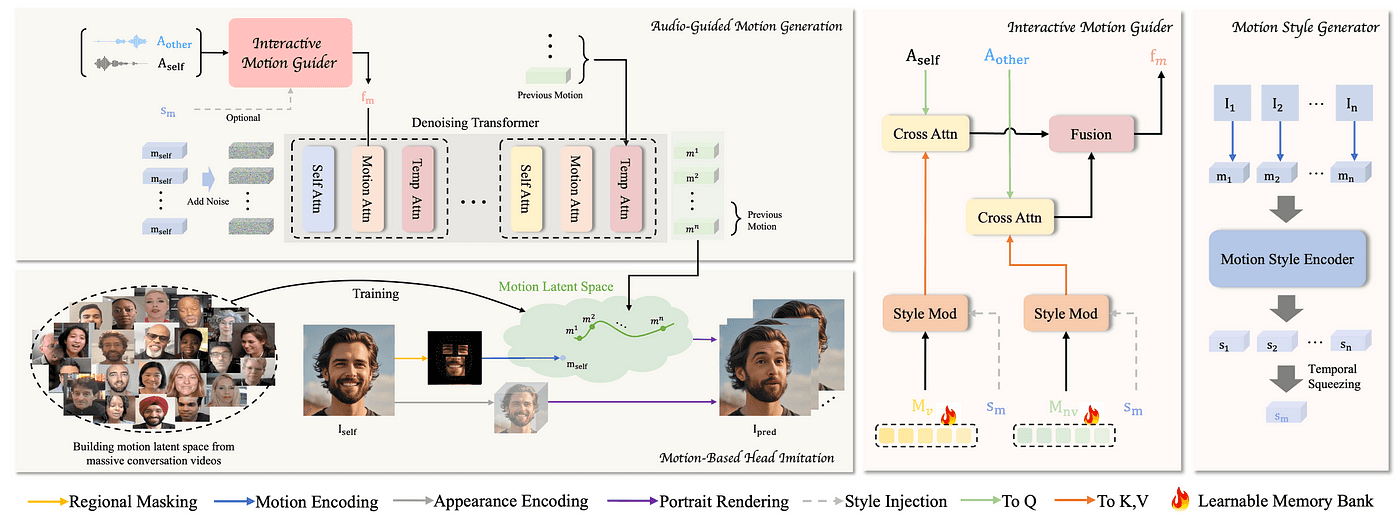
<반응형 토킹 포토 예시. INFP>
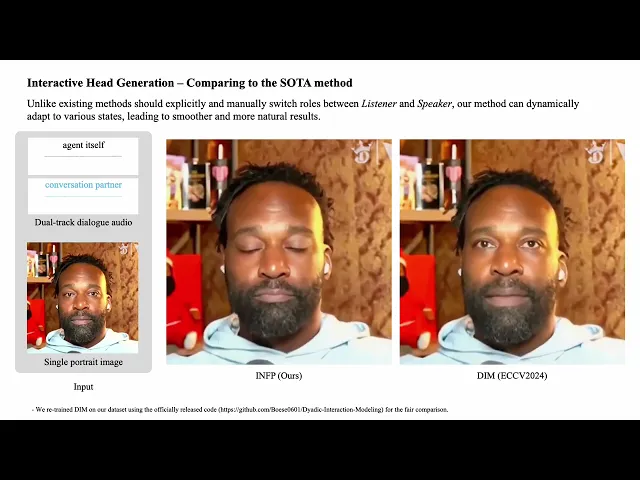
<반응형 토킹 포토 예시. INFP>
반응형 토킹 포토는 사용자의 말에 반응하는 AI 기술을 지칭합니다. 이러한 기술을 이용했을 때, 실제 사용자가 AI 아바타와의 대화에서 더 높은 사용자 경험을 얻지 않을까요? 지금까지의 토킹 포토 기술을 “speaking” photo 라고 한다면, 이 반응형 토킹 포토는 “listening” photo 기술까지 접목된 기술이라고 볼 수 있습니다. 가장 대표적인 최신 연구인 INFP (CVPR 2025) 는 “본인이 말하는 음성”과 “본인이 아닌 다른 사람이 말하는 음성”을 처리하는 각각의 memory network를 두어, 립싱킹 같은 화자의 움직임 (speaking motion)과 고개 끄덕임, 맞장구 같은 청자의 움직임 (listening motion)을 모두 인식하며 움직이는 토킹포토 기술을 제안했습니다.
이러한 반응형 토킹포토 기법은 아무래도 실시간으로 사용자의 음성이나 반응을 읽어야 하기 때문에, 굉장히 효율적인 알고리즘으로 구성해야한다는 어려움이 있습니다.
앞서 소개한 두 방향이 현재 학계에서 주목할 만한 토킹 포토 기술의 발전 방향입니다.
5. 마치며
브이몬스터는 기존의 토킹 포토 기술을 넘어, AI 아바타의 사실성과 몰입감을 극대화하기 위한 차세대 기술 개발에 주력하고 있습니다. 특히, 실시간 립싱킹, 토킹 포토 기술에 더 나아가, 상반신의 손 동작 및 몸 동작 생성과 반응형 대화 기능을 중심으로 연구를 진행하고 있습니다. 이러한 기술들을 통합하여, 단순히 말하는 아바타를 넘어 감정을 표현하고, 제스처를 통해 소통하며, 실시간으로 반응하는 진정한 AI 아바타를 구현하고자 합니다. 이를 통해 사용자에게 더욱 몰입감 있는 대화 경험을 제공할 수 있을 것으로 기대합니다.
