


몸까지 움직이는 Agent: Human Animation 기술의 진화
VMONSTER TEAM
2025. 9. 1.
안녕하세요. VMONSTER의 AI Engineer 강윤수입니다.
지난 블로그 글에서는 토킹 포토 생성 연구의 전반적인 흐름을 소개해드렸는데요. 오늘은 그 연장선상에서, 얼굴을 넘어 손짓, 상반신, 전신 움직임까지 생성하는 ‘Human Animation’ 기술에 대해 이야기해보려 합니다.
서비스 속 AI 아바타가 사용자의 말에 반응하며 손을 흔들거나 고개를 끄덕이고, 더 나아가 가상 공간에서 진짜 사람처럼 걸어다니며 함께 반응하는 나만의 친구가 생긴다면 어떨까요? 단순히 정보를 전달하는 도구를 넘어서, 정서적 교감까지 가능한 인터페이스가 될 수 있을지도 모릅니다.
오늘은 이러한 Human Animation 기술이 어디까지 왔고, 어떤 방향으로 진화하고 있는지를 중심으로 함께 살펴보겠습니다.
1. 영상 생성 기반 Human Animation
1.1 비디오를 따라 움직이는 영상 생성 : GAN 기반 방식의 시작
초기의 Human Animation 연구는 사람이 움직이는 비디오가 주어졌을 때, 인물 사진을 움직이게 하는 방식으로 시작됐습니다. 이때는 GAN(Generative Adversarial Network)이라는 모델이 사용되었는데요, GAN은 두개의 신경망이 경쟁하듯 학습하며 더욱 사실적인 이미지를 생성하는 방식으로, 이미지 합성 분야에서 널리 활용되어 왔습니다.
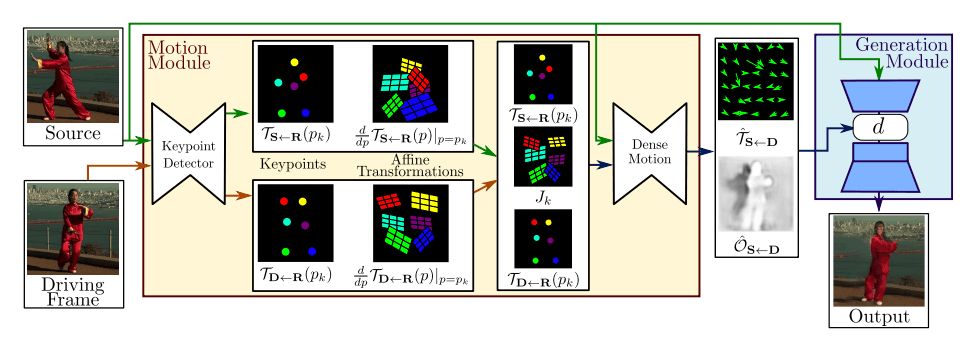
<GAN 기반 방식: First Order Motion Model>
대표적인 예는 First Order Motion Model (NeurIPS 2019)입니다. 이 모델은 ‘레퍼런스 이미지(정지된 얼굴 사진)’와 ‘타겟 비디오(움직이는 참조 영상)’를 입력으로 받아, 레퍼런스 이미지가 타겟 비디오의 움직임을 따라하도록 영상 전체를 생성합니다.
이 모델은 중요한 키포인트를 추출하고, 타겟 비디오에서는 이 위치들이 어떻게 움직였는지를 계산합니다. 그리고 이 움직임을 레퍼런스 이미지에 적용해, 정지된 사진이 점점 움직이는 것처럼 보이도록 만드는 방식입니다. 이 방식은 비교적 간단하고 직관적이며 빠르게 결과를 만들 수 있다는 장점이 있습니다.
하지만 움직임이 너무 크거나, 팔이나 몸이 다른 물체에 가려진 경우, 혹은 옷이나 배경이 복잡할 때는 어색하게 일그러지거나 이상한 결과가 나올 수 있습니다. 게다가 GAN이라는 기술 특성상, 학습이 불안정해 결과 품질이 들쭉날쭉할 수 있다는 점도 한계로 지적됩니다.
1.2 Diffusion 기반으로의 전환 : Pose-driven Human Aninmation
이러한 GAN 방식의 한계들을 극복하기 위해 최근에는 Diffusion 기반으로 연구 방향이 전환되었습니다. 특히 Stable Diffusion처럼 이미지 생성 분야에서 큰 성과를 낸 기술들이 영상 생성 쪽으로 확장되면서, 움직이는 사람의 영상을 생성하는 연구도 활발히 진행되고 있죠.
특히 이미지를 latent 공간으로 임베딩화하고, 특정 조건(ex. 원하는 타겟 움직임)에 맞춰 조작한 뒤 이미지로 복원하는 방식은, 고해상도 이미지를 효율적으로 다루면서도 표현력을 확보할 수 있다는 점에서 주목받고 있습니다.
이러한 방식은 pose-driven Human Animation 분야에서도 적극 활용되고 있습니다. 예를 들어, 한 장의 인물 사진(레퍼런스 이미지)과 함께 사람이 어떤 식으로 움직일지를 정의한 포즈 시퀀스를 입력으로 받아, 노이즈에서 점차 사람이 움직이는 모습을 생성해나가는 방식입니다.
이러한 흐름 속에서 초기에 등장했던 대표적인 예는 Animate Anyone (CVPR 2024)입니다. 이 모델은 인물 사진 한 장과 원하는 움직임이 담긴 포즈 시퀀스를 2D 스켈레톤 형식으로 받아 사진 속 인물이 움직이는 비디오를 생성합니다. Stable Diffusion에서 사용된 사전 학습된 모델을 바탕으로 Denoising UNet을 구성하고, 여기에 ReferenceNet이라는 별도의 네트워크를 결합해, 원본 이미지 속 인물의 생김새나 스타일이 결과 영상에 잘 녹아들 수 있도록 설계된 것이 특징입니다.
다만, 이 방식 역시 한 장의 이미지에서 출발하다 보니 보이지 않는 영역(예: 옆모습, 등)에 대한 정보가 부족하고, 손가락처럼 섬세한 움직임에서는 artifact가 발생하는 등 한계점도 존재했습니다.

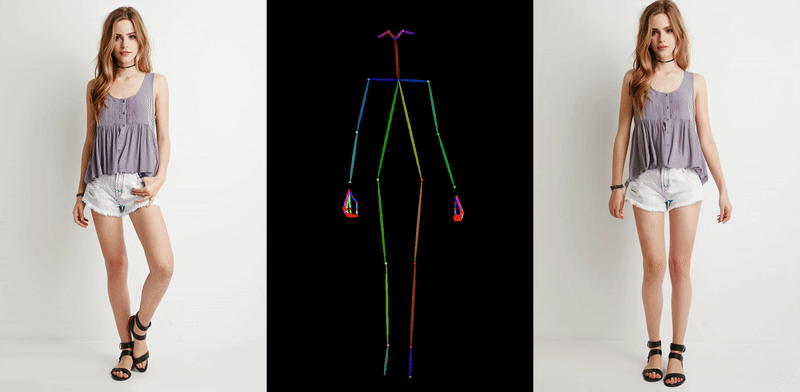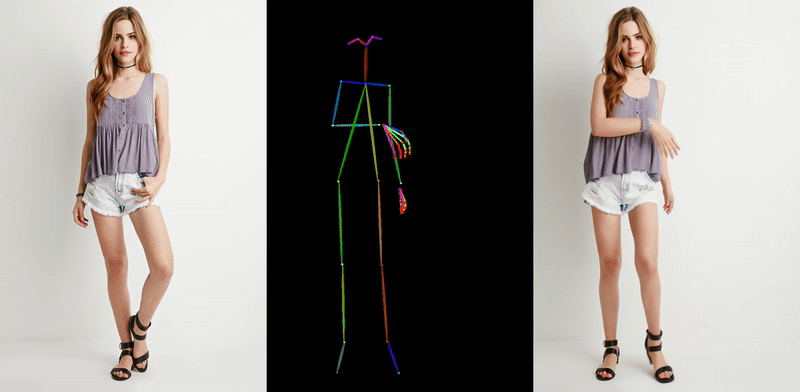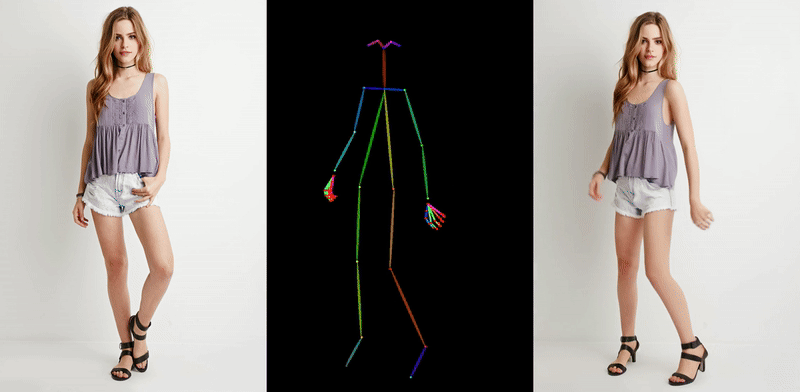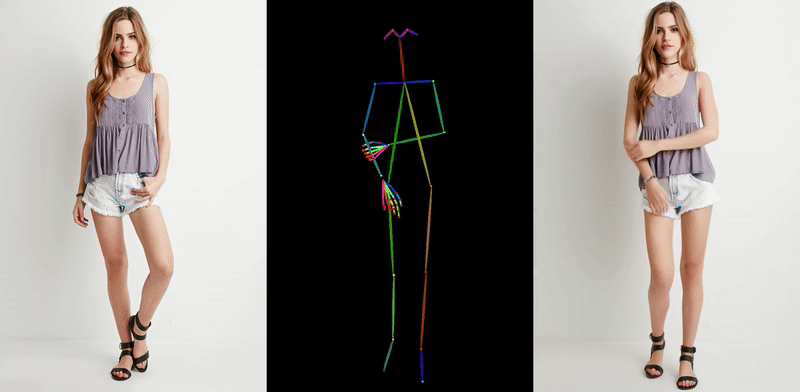
<포즈 시퀀스 기반 diffusion 모델 예시: Animate Anyone>
이후 등장한 MimicMotion(ICML 2025) 또한 기본적인 구조는 Animate Anyone과 유사하게, 인물 사진 한 장과 포즈 시퀀스를 입력으로 받아 사람이 움직이는 영상을 생성합니다. 하지만 MimicMotion은 특히 손과 같이 디테일한 부위에서의 표현력 향상에 집중했습니다.
이를 위해 포즈 정보의 신뢰도(confidence score) 를 활용하여, 신뢰도가 높은 포즈 정보에 집중해 영상을 생성하도록 설계했고. 특히 신뢰도 점수가 높은 손 영역에 대하여 학습 시 가중치를 높여 손의 디테일 품질을 끌어올렸습니다. 또 하나 눈에 띄는 점은, 긴 영상도 부드럽게 생성할 수 있도록 제안된 Progressive Latent Fusion 기법입니다. 긴 포즈 시퀀스를 여러 구간으로 나누되, 일부 프레임을 서로 겹치게 설정해 각 구간을 따로 생성한 뒤 자연스럽게 이어 붙이는 방식으로, 끊김 없는 매끄러운 영상 생성을 가능하게 했습니다.


<Pose-driven Diffusion 방식 예시: MimicMotion>
Human4DiT (SIGGRAPH ASIA 2024)는 기존 Human Animation 기법들이 주로 정면 시점에서의 움직임 생성에 초점을 맞췄던 것과 달리, 사람이 움직이는 모습이 다른 방향에서 어떻게 보일지를 함께 생성하는 4차원(4D) Human Animation을 목표로 합니다.
이 모델은 기존처럼 인물 사진(레퍼런스 이미지)과 포즈 시퀀스를 입력으로 받는 데 더해, 영상이 어떤 카메라 시점에서 보일지를 결정하는 카메라 정보까지 함께 입력으로 사용합니다. 또한 2D 스켈레톤 포즈 대신, 사람의 몸을 3D로 표현할 수 있는 SMPL 포맷의 포즈 정보를 사용하여, 다양한 시점에서 사람의 형태와 움직임을 보다 정확히 반영할 수 있도록 설계되었습니다.
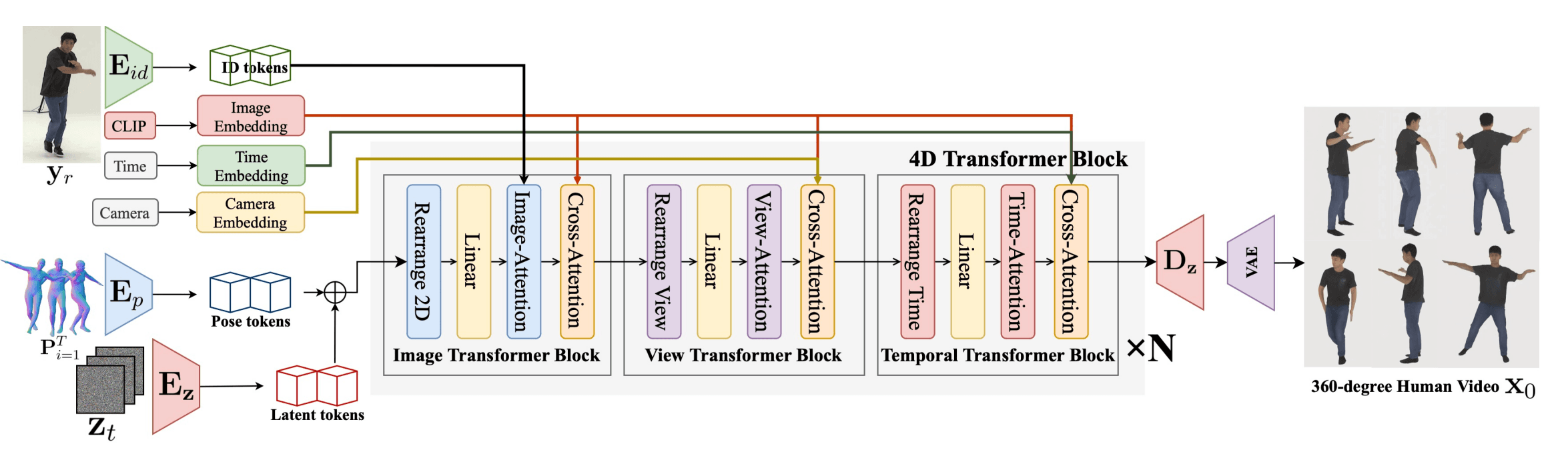
Press enter or click to view image in full size

<다양한 시점에서의 휴먼 애니메이션 영상을 만들 수 있는 Human4DiT>
아키텍처 측면에서는 단순한 이미지 공간만을 다루던 기존 CNN 방식에서 벗어나, 시간 + 시점 + 공간 정보를 동시에 처리할 수 있는 4D Diffusion Transformer를 제안해, 시간 흐름 속에서도 시점이 바뀌는 장면을 자연스럽고 일관되게 생성할 수 있도록 구성되어 있습니다.
1–3. 음성 기반 Human Animation
지금까지 위에서 살펴본 연구들은 모두 따라할 움직임이 담긴 비디오나 포즈 정보를 입력으로 활용했습니다. 하지만 비디오가 아닌, 사람의 목소리만으로 손짓이나 몸짓이 자연스럽게 생성된다면 어떨까요? 영상 없이도 더욱 간편하게, 그리고 몰입감 있는 아바타를 만들 수 있게 됩니다.
음성 기반 Human Animation은 말하는 음성의 리듬, 억양, 감정 등을 고려해 얼굴 표정이나 몸짓을 자연스럽게 생성하여 영상을 생성하는 기술입니다. 이전에도 관련 연구들은 있었으나, 최근에는 diffusion 모델의 등장과 성능 향상 덕분에 이 영역에서도 획기적인 발전이 일어나고 있습니다.
예를 들어, VLOGGER (CVPR 2025)는 레퍼런스 이미지와 오디오 입력만으로, 상반신이 자연스럽게 움직이며 말하는 사람의 영상을 생성하는 모델입니다. 두 단계로 구성된 구조로, 1단계에서는 Diffusion 기반 모션 생성기가 오디오의 억양, 감정 등을 반영해 얼굴 표정 과 상반신 동작을 생성하고, 2단계에서는 이를 바탕으로 고해상도 영상을 생성합니다. 특히, 손의 움직임이나 얼굴 이외의 부분에서 흔히 발생하던 artifact 문제를 줄이기 위해 MENTOR라는 대규모 데이터셋(800,000명, 2,200시간 분량)을 활용해 학습한 점이 눈에 띕니다.
비슷한 접근을 한 CyberHost (ICLR 2025)은 한층 더 발전된 방식을 제안합니다. VLOGGER처럼 두 단계를 거치지 않고, 하나의 모델에서 음성과 이미지를 바탕으로 한번에 영상을 생성한다는 점이 큰 특징입니다. 포즈 시퀀스라는 중간 표현 단계를 사용하지 않음으로써 부정확한 포즈 시퀀스으로부터 오는 에러를 줄일 수 있고, 제한된 표현력 문제를 해결할 수 있습니다. 여기서도 200시간 분량과 약 10,000명의 사람에 대한 데이터를 자체적으로 구축했다고 합니다.
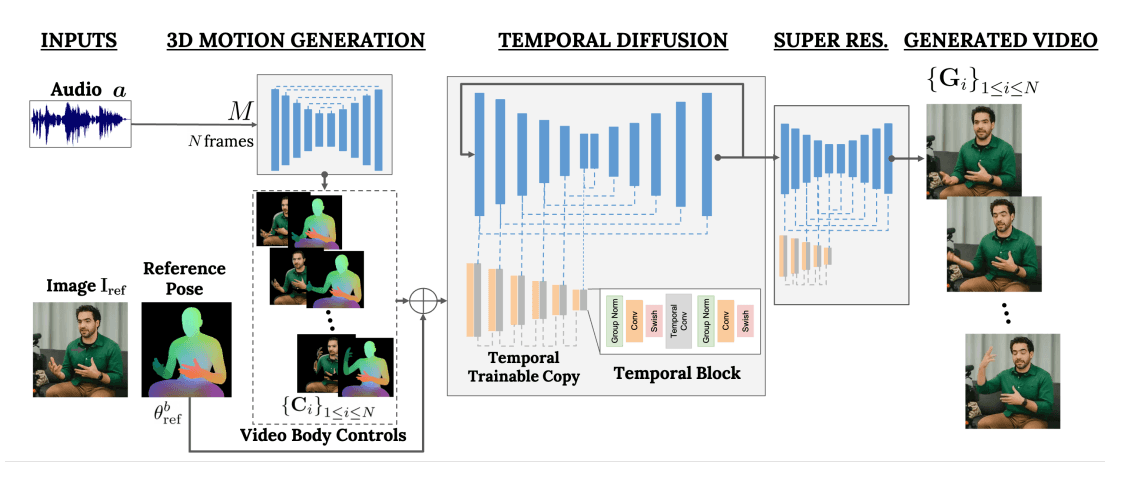
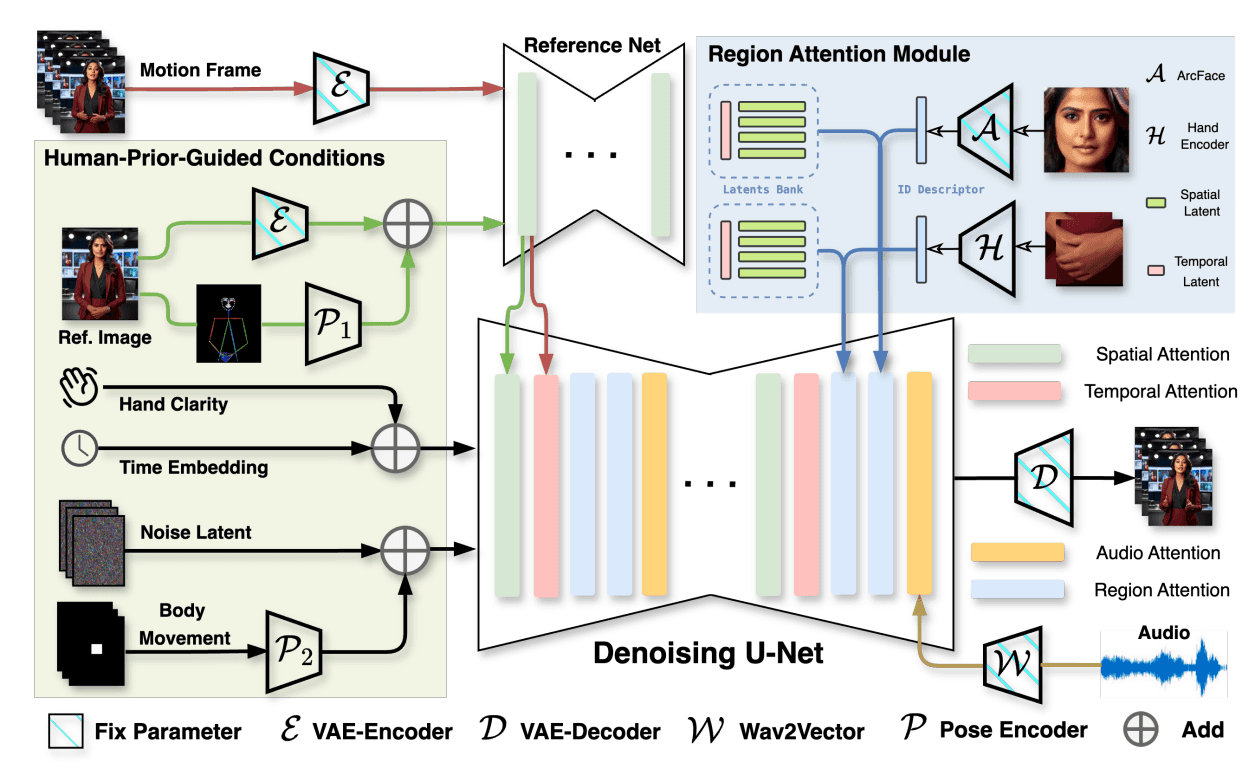
<음성으로 사람을 움직이는 diffusion 모델 예시: (좌) VLOGGER, (우) CyberHost>

<음성으로 human animation을 하는 diffusion 모델 예시: VLOGGER, CyberHost>
여기서 더 나아가서, OmniHuman (arXiv 2025)은 레퍼런스 이미지 한 장과 함께 음성, 포즈, 텍스트의 3가지 조건을 복합적으로 입력받아 사람의 움직임을 생성할 수 있도록 설계되었습니다.


<음성, 포즈, 텍스트 3가지 방식으로 사람을 움직이는 OmniHuman>
이 모델은 총 3단계 학습 전략을 따릅니다. 1단계에서는 텍스트+이미지만으로 기본 동작을 학습하고, 2단계에 오디오 조건을 추가, 마지막 3단계에서 포즈까지 포함해 모든 조건을 함께 학습합니다.
이 때, 오디오처럼 얼굴 표정 등 좁은 영역에만 영향을 주는 ‘약한 조건’은 더 많이 학습하고, 포즈처럼 넓은 영역에 영향을 주는 ‘강한 조건’은 비교적 적은 빈도로 학습시켜, 모델이 전신 동작과 표정 표현을 균형 있게 학습할 수 있습니다. 추가적으로, 오디오 싱크가 맞지 않거나 포즈 정보가 부족한 데이터더라도 텍스트 기반 학습에서 재활용함으로써 전체 학습 데이터의 손실을 줄일 수 있었습니다.
이처럼 기존 오디오 기반 모델들이 얼굴 표현에만 집중했다면, OmniHuman은 손짓과 몸 전체의 리듬까지 담아내며 진짜 사람과 대화하는 듯한 몰입감을 제공하여 업계의 관심을 받고있습니다.
2. 3D Modeling 기반 Human Animation
위에서 설명한 영상 생성 기반 모델들은 연속된 2D 이미지 프레임을 생성해서 영상을 만든다면, 최근에는 3D 모델링 기반의 아바타 생성 기술도 빠르게 발전하고 있습니다. 특히 NeRF(Neural Radiance Fields)나 Gaussian Splatting과 같은 최신 표현 기법은 사실적인 아바타 렌더링과 실시간 추론을 동시에 달성하기 위한 핵심 기술로 주목받고 있습니다.
그중 대표적으로 TaoAvatar (CVPR 2025)는 실시간으로 작동 가능한 고화질 전신 3D 아바타를 생성하기 위해 개발된 최신 3D Gaussian Splatting 기반 기술입니다. 기존의 고정밀 스캔 모델들이 갖는 느린 렌더링 속도와 높은 계산 비용의 한계를 극복하기 위해, TaoAvatar는 옷까지 표현 가능하도록 SMPLX라는 3D 아바타 템플릿 모델과 3DGS를 결합한 구조를 제안했습니다. 특히, 경량화를 통해 AR 디바이스에서도 2K 해상도, 90FPS의 빠른 속도로 동작할 수 있게 최적화했습니다. 다양한 표정과 제스처, 음성이 동기화된 전신 아바타 데이터셋인 TalkBody4D를 함께 제안하며, 몰입감 높은 인터랙티브 아바타 서비스의 실현 가능성을 크게 높였습니다.
3. 마치며
지금까지 다양한 Human Animation 기술들을 살펴봤습니다. GAN 기반의 초기 방식부터, 포즈와 음성 정보를 활용한 diffusion 모델, 나아가 3D 기반의 전신 아바타 기술까지, 사람처럼 보이고, 사람처럼 소통할 수 있는 AI 아바타를 구현하기 위한 방향으로 빠르게 진화하고 있습니다.
다만, 아직 해결해야 할 현실적인 과제도 남아 있습니다.
먼저 데이터 측면에서의 제약이 있습니다. 얼굴 이외의 부위, 손이나 몸 전체의 자연스러운 움직임을 학습하기 위해서는 동작 정보가 담긴 고품질의 대규모 멀티모달 데이터셋이 필요한데, 비교적 최신 분야이다 보니 공개된 데이터셋이 많이 없고, 시간과 비용 모두 큰 부담이 듭니다.
생성 시간과 연산 리소스 최적화도 중요한 과제입니다. 예를 들어, Diffusion 기반 방식은 고품질 이미지를 생성할 수 있지만, 여러 단계에 걸쳐 노이즈를 제거해나가는 연산 과정에서 GPU 자원을 많이 요구하고 속도가 느립니다.
실제 서비스 환경에서 실시간으로 반응하는 아바타를 만들기 위해서는 경량화된 모델 아키텍처나 streaming 기반의 응답 구조가 필요합니다. 물론 지금도 고성능 GPU를 사용하면 실시간 처리가 가능하지만, 상용화가 되려면 더욱 값싼 GPU에서도 실시간 추론이 가능할 정도로 최적화에 대한 고민이 필요합니다.
이처럼 Human Animation 기술은 단순히 ‘움직이는 얼굴’을 넘어서, 음성에 적합한 손짓, 몸짓까지 생성하며 더 사람다운 움직임을 만들어내는 방향으로 진화하고 있습니다. 브이몬스터도 이러한 기술 흐름에 맞춰, 상반신 동작 생성 기술을 실시간 상용화 수준으로 구현하기 위해 연구를 진행 중입니다. 궁극적으로는 단순히 말만 하는 아바타를 넘어 실시간으로 사용자의 말에 반응하고, 해당 시점에 적합한 몸 제스쳐와 감정 표현까지 가능한 AI 아바타를 구현하여, 사용자들이 더욱 대화에 몰입할 수 있게 하는 것이 목표입니다.
다음에 기회가 된다면 휴먼 아바타의 다른 기술들에 대해 소개하는 블로그로 찾아 뵙겠습니다.
